
Tribune co-écrite avec Nicolas Chanut
Depuis la révolution de l’information et des télécommunications au début des années 1990, le vieil adage « knowledge is power », attribué à Sir Francis Bacon, n’a jamais été aussi actuel. Pour survivre et se développer, les entreprises ont plus que jamais besoin de connaître les attentes de leurs clients, de prévoir le moment et l’endroit dans la chaîne de production où la panne est la plus risquée, ou d’anticiper la demande pour mieux pouvoir y répondre, au risque de perdre des marchés contre des organisations qui, elles, ont ces informations. Cette « course à l’information » est si prégnante que l’on pourrait même préciser cette citation en « better knowledge is higher market power ».
Aujourd’hui, la plupart des entreprises sont conscientes de l’importance de la donnée, et de l’information qu’elle convoie. Néanmoins, toutes ces entreprises n’en sont pas au même point dans leur appropriation de celle-ci. Les organisations modernes, que nous appelons Open Organisations (Organisations Ouvertes) comportent 5 spécificités. Le fait d’être data driven est l’une d’entre elles.
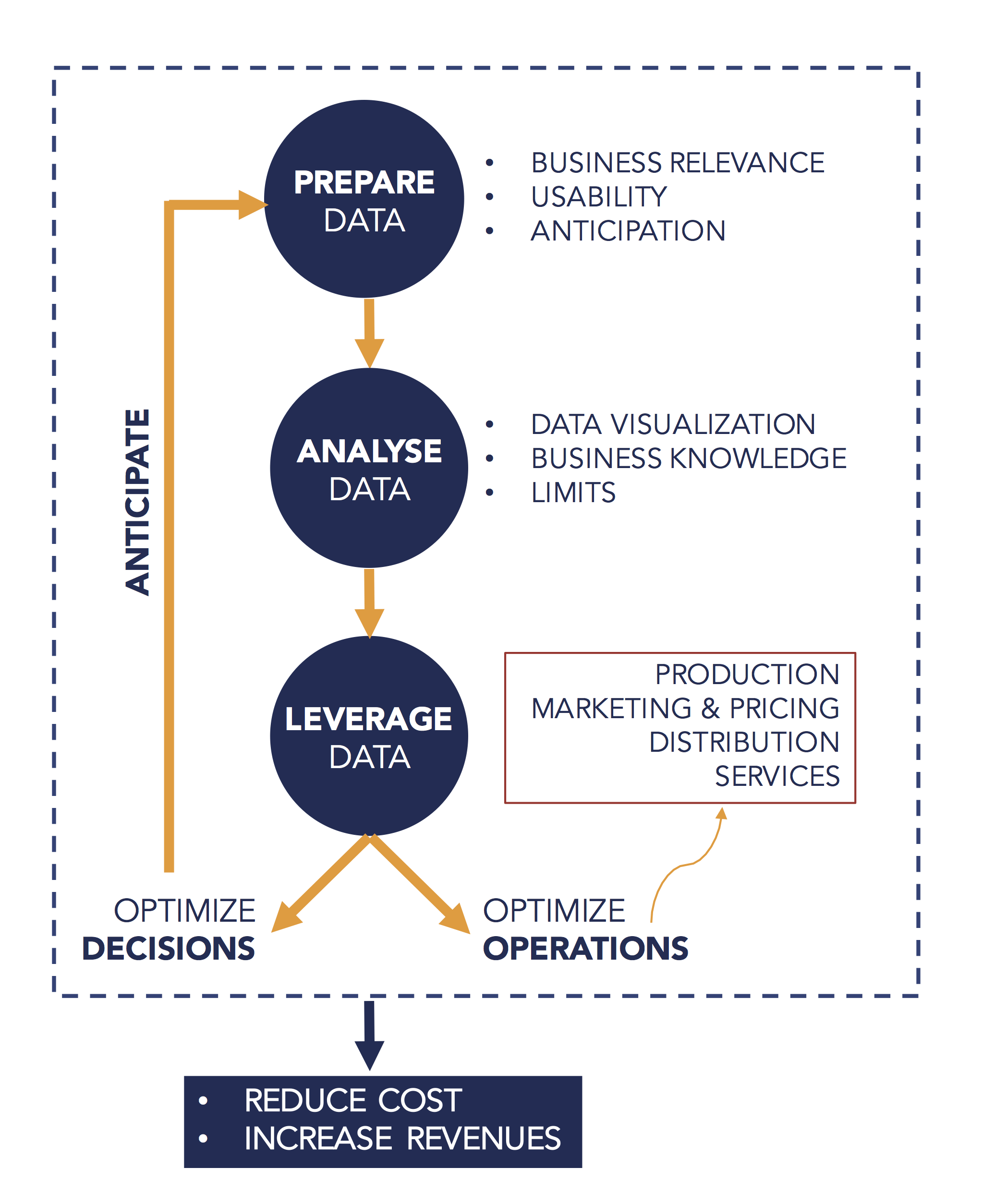 Chez Presans, nous distinguons trois étapes pour devenir une entreprise (ou une organisation) data driven.
Chez Presans, nous distinguons trois étapes pour devenir une entreprise (ou une organisation) data driven.
La première étape consiste à identifier, gérer et organiser les données nécessaires aux organisations. La plupart des entreprises ont déjà développé une réflexion à ce sujet. La deuxième étape consiste à construire une capacité d’analyse des données. Cette étape est beaucoup plus complexe : les entreprises font régulièrement appel à des cabinets de conseil ou autres startups spécialisés. Cette phase repose avant tout sur une interaction optimale entre connaissance du secteur et savoir-faire technique d’analyse des données. La dernière étape consiste à utiliser l’information extraite des données pour optimiser les processus et optimiser les prises de décisions.
Dans ce qui suit, nous décrivons plus en détail ces trois étapes.
Etape #1 – PREPARE : identifier, gérer et organiser les données
La première étape pour devenir data driven est d’identifier, gérer et organiser les données essentielles à l’organisation. L’idée-force de cette phase est de réaliser que, en dépit de l’utilisation de plus en plus fréquente du terme « big data », ce qui compte n’est pas la quantité, mais bien la qualité des données. En particulier, cela se conjugue en trois principes.
Principe 1 : pertinence « business » des données
Les données doivent répondre à un problème concret de l’entreprise. Il est souvent dangereux, et coûteux en termes de temps et d’argent, d’amasser le plus de données possibles sans trop savoir comment les utiliser ensuite. A l’inverse, il est préférable de partir du problème business, et de répondre avec un grand niveau de précision aux deux questions suivantes « Quels sont les enjeux majeurs de mon organisation pour les 5 prochaines années ? De quelles informations ai-je besoin pour pouvoir répondre correctement à ces enjeux ? ».
Principe 2 : utilisabilité des données
Une fois les données récoltées, une des étapes essentielles dans leur valorisation est de les transformer en quelque chose d’exploitable. Tous les data scientists s’accordent à dire que 80% de leur travail consiste à faire du data cleaning, à mettre en forme les données. Il existe de nombreux critères pour définir si une base de données est suffisamment propre et standardisée, en voici quelques-uns, qui reviennent régulièrement et s’appliquent à presque toutes les situations.
- La base peut facilement être mise à jour : cela permet de disposer des données quasiment en temps réel ;
- La base peut être facilement croisée avec d’autres informations ;
- La base doit être maniable : l’architecture de la base et la puissance de calcul doivent être adaptées à une exploitation « temps réel ».
Principe 3 : Anticipation
Appliquer les principes 1 et 2 ci-dessus demande une capacité d’anticipation que la plupart des entreprises commençant leur transformation digitale sous-estiment. Il est donc essentiel d’anticiper autant que possible les besoins en termes de données (pertinence) et de leur utilisation (utilisabilité).
Par exemple, une grande administration française a lancé il y a 5 ans un programme visant à promouvoir l’innovation en son sein. Cependant, les gestionnaires de ce programme n’ont pas pensé lors de sa conception aux métriques qui permettraient d’évaluer son efficacité. Résultat : les données n’existent pas et l’impact de ce programme est difficilement évaluable. Une bonne manière de ne pas tomber dans ce type de problème consisterait, par exemple, à mettre en place, pendant une durée de quelques semaines, un programme pilote afin d’identifier les difficultés et les données nécessaires à leur élimination.
Etape #2 – ANALYSE : construire une capacité d’analyse des données
Il est beaucoup plus difficile de construire une excellente capacité d’analyse de ces données. Cela tient au fait que cela demande une excellente interaction entre savoir-faire technique d’analyse des données et connaissance du secteur en particulier. En particulier, on peut souligner trois aspects fondamentaux qui permettent d’identifier une analyse de qualité.
Aspect 1 – DATA VISUALIZATION : ce qui se conçoit bien se visualise clairement
Réduire l’information contenue dans des millions de data points en un message facilement compréhensible est une véritable compétence, qui peut faire la différence au sein d’une organisation. En particulier, depuis l’émergence du big data, la plupart des spécialistes de l’apprentissage s’accordent pour affirmer que rien ne vaut un graphique ou une image intéressante pour identifier et communiquer rapidement les enjeux importants. A tel point que de nos jours, la fameuse phrase de Boileau devrait être reformulée en : « ce qui se conçoit bien se visualise clairement ». Ainsi, une organisation qui est data driven, devrait avoir en interne non seulement les capacités pour récolter les données dont elle a besoin, mais aussi pour les visualiser. Par exemple, le TED talk de David McCandless montre comment la simple visualisation des données permet d’identifier les patterns dans les données.
Aspect 2 – CONNAISSANCE METIER : savoir à quelle(s) question(s) ne répond pas l’analyse
Comprimer autant d’information en un seul graphe demande à l’analyste de faire des choix : est-ce que je préfère montrer l’évolution du nombre de pièces défaillantes produites par cette machine en valeur absolue, ou relativement par rapport au nombre total de pièces produites ? Ce choix dépend de la question à laquelle on souhaite répondre. Si je me suis engagé à payer contractuellement des dommages et intérêts pour chaque pièce défaillante, je suis intéressé au chiffre absolu ; si je veux mesurer l’efficacité de cette machine, je m’intéresse plutôt au chiffre relatif. Cet exemple cherche à montrer deux choses. D’abord, le pouvoir et la responsabilité qu’ont les individus qui manient les données, car leurs choix ne sont pas neutres. Ensuite, qu’un savoir-faire technique d’analyse (data visualisation, machine learning, etc.) doit aller de pair avec une connaissance stratégique du secteur. Ainsi, lorsqu’on étudie un graphique, il est impératif de se demander aussi à quelles questions celui-ci ne répond pas.
Aspect 3 – LIMITES : être conscient des limites des outils employés
Enfin, une organisation data driven est consciente des limites de l’intelligence artificielle, malgré l’importance de celle-ci et de l’effet de mode qui l’entoure. Pour comprendre ces limites, il faut comprendre comment fonctionnent les algorithmes de machine learning, qui sont utilisés pour faire entre autres de la maintenance prédictive. Tous fonctionnent selon la même logique : l’algorithme est entraîné à repérer des constances et des récurrences dans une base de données. Ce que presque personne ne prend la peine de souligner, cependant, c’est que ces algorithmes assurent une prédiction de qualité à environnement constant. Il est donc important de réaliser que si l’environnement change brusquement (catastrophe climatique empêchant les communications par satellite, entrée dans un secteur d’un « barbare du net » bouleversant les équilibres, etc.), les prédictions faites sur les données seront de moins bonne qualité.
Etape #3 – LEVERAGE : utiliser les données pour optimiser les opérations et les prises des décisions
Une Organisation Ouverte utilise les données qu’elle a préparées et analysées de deux grandes manières. Pour optimiser ses opérations d’abord, et pour optimiser ses prises de décision (stratégiques), ensuite.
Axe 1 : Optimiser les opérations pour réduire les coûts et augmenter les revenus
Les organisations qui sont data driven utilisent la donnée pour optimiser toutes les strates de leurs opérations, que ce soit pour réduire les coûts ou pour augmenter les revenus.
- Production : les entreprises comme Airbus ou Renault utilisent la donnée tout au long de leur cycle de production, par exemple pour suivre l’évolution de leurs unités sur leur chaîne de montagne, pour identifier les problèmes et les sources de défaillance, ou pour réduire la consommation d’énergie.
- Marketing et pricing : selon le cabinet de conseil McKinsey, c’est dans la vente et le marketing que l’intelligence artificielle peut apporter le plus de valeur au cours des 20 prochaines années, notamment pour prédire la demande pour certains produits avec une précision inégalée. Par exemple, Amazon peut prédire la demande pour des millions de produits jusqu’à 18 mois à l’avance. D’autres algorithmes permettent d’optimiser les prix pour les fixer au plus près de ce qu’un client est prêt à payer au maximum en moyenne en fonction de ses caractéristiques. Cela est déjà commun chez les compagnies aériennes mais a vocation à se généraliser dans d’autres secteurs avec le développement des grandes bases de données.
- Distribution : l’intelligence artificielle joue un rôle essentiel pour optimiser la distribution. Par exemple, Ocado, une entreprise de commerce en ligne britannique, utilise des technologies issues du contrôle aérien pour optimiser la préparation et la livraison de ses commandes.
- Service client : enfin, l’utilisation de la donnée et de l’intelligence artificielle permet de fournir un service client de qualité supérieure. Les constructeurs automobiles offrent maintenant des services de maintenance prédictive afin prédire quand et de quelle manière les voitures doivent être révisées. La maintenance prédictive est aussi particulièrement importante pour le secteur du pétrole et du gaz, car les entreprises doivent gérer d’immenses infrastructures.
Axe 2 : Optimiser les prises de décision (stratégique) en limitant les biais cognitifs
Le second axe d’utilisation des données et de leur analyse est l’optimisation des décisions. Prendre une décision (stratégique) sans la justifier quantitativement est aujourd’hui inacceptable. La « data analytics » devient donc un outil nécessaire (mais, on l’a vu plus haut, non suffisant) à la prise de décision, et surtout pour convaincre que la décision prise est la bonne. En particulier, une utilisation pertinente des données disponibles permet de limiter certains biais cognitifs[1] comme l’excès de confiance ou l’ancrage. L’excès de confiance est le biais qui consiste à « croire à sa bonne étoile », à croire que notre expérience personnelle n’est pas sujette aux mêmes aléas que celle des autres. Par exemple, les individus surestiment leurs chances de retrouver du travail lorsqu’ils sont au chômage par rapport à la durée moyenne chez les personnes ayant des caractéristiques similaires ; les managers ont tendance à surestimer les chances de succès du projet qu’ils portent par rapport aux projets qu’ils ne portent pas aux caractéristiques similaires. Dans ces cas-là, utiliser des modèles de prédiction peut apporter une lumière plus objective en soulignant justement qui sont les individus ou projets « aux caractéristiques similaires » et ce qu’on peut apprendre d’eux.
De la même manière, nous souffrons tous d’« ancrage » dans nos prises de décision, ce qui signifie simplement qu’il est difficile de passer outre la première impression. Si j’ai déjà été au chômage six mois et que je le suis de nouveau aujourd’hui, je vais avoir tendance à anticiper un chômage d’à peu près six mois aussi, même si les conditions ont radicalement changé. De la même manière, si 6 de mes 10 projets ont été couronnés de succès l’année dernière, je vais avoir tendance à anticiper un taux de succès d’à peu près 60%, disons 70% si je suis ambitieux. Une analyse plus précise des données pourrait au contraire m’indiquer que je suis en droit d’espérer un taux de succès de 90% au vu de l’environnement actuel, et peut m’amener à prendre une décision informée de manière plus objective.
En substance, une organisation data driven, c’est une organisation qui utilise la donnée dans tous les aspects de son activité, tout en comprenant ses limites.
[1] Je sais ce que vous pensez !, Rémi Larrousse (2018)

